Multiverse Computing Launches Pulsar 16B in collaboration with NVIDIA: Frontier-Grade Reasoning at Half the Parameters
The new open reasoning model delivers 30B-class intelligence in a 16B-parameter footprint, with 3.1B active parameters, validated independently on NVIDIA accelerated computing infrastructure.
DONOSTIA, Spain, June 23, 2026 (GLOBE NEWSWIRE) -- Multiverse Computing today announced the release of Pulsar 16B, a 16.15B-parameter open reasoning model built on NVIDIA Nemotron architecture. Developed using Multiverse Computing’s proprietary technology, leveraging NVIDIA Model Optimizer and Megatron Bridge libraries as part of the compression workflow, and validated on NVIDIA accelerated computing infrastructure, Pulsar 16B delivers the reasoning performance of leading 30B-class architectures at roughly half the parameter count. Available in BF16, FP8, and NVFP4 precisions, the model is available on HuggingFace under the Apache 2.0 license.
Pulsar 16B preserves most of the reasoning quality, instruction-following behavior and tool-use interfaces of the uncompressed base model — independently validated on NVIDIA accelerated computing. Across standard reasoning, knowledge, coding, and tool-use benchmarks, Pulsar 16B matches its 30B-class starting point and outperforms gpt-oss-20B on nearly every measure despite being smaller than both. Key benchmarks include:
- AIME 2025: Pulsar 16B scores 87.22, within a tenth of a point of the uncompressed base model and 15 points ahead of gpt-oss-20B.
- GPQA-Diamond (PhD-level science): 71.41, matching the uncompressed model and well ahead of gpt-oss-20B at 58.88.
-
Production-critical capabilities: Pulsar 16B outperforms gpt-oss-20B by 14 points on instruction following (IFBench), 11 points on function calling (BFCL-v4), and 15 points on math reasoning (AIME).
Memory savings and inference performance
Pulsar 16B achieves substantial reductions in model weight memory across all supported precisions compared to the Nemotron-3-Nano-30B-A3B base model, a crucial advantage for organizations deploying on lower-memory GPUs or single-node environments:
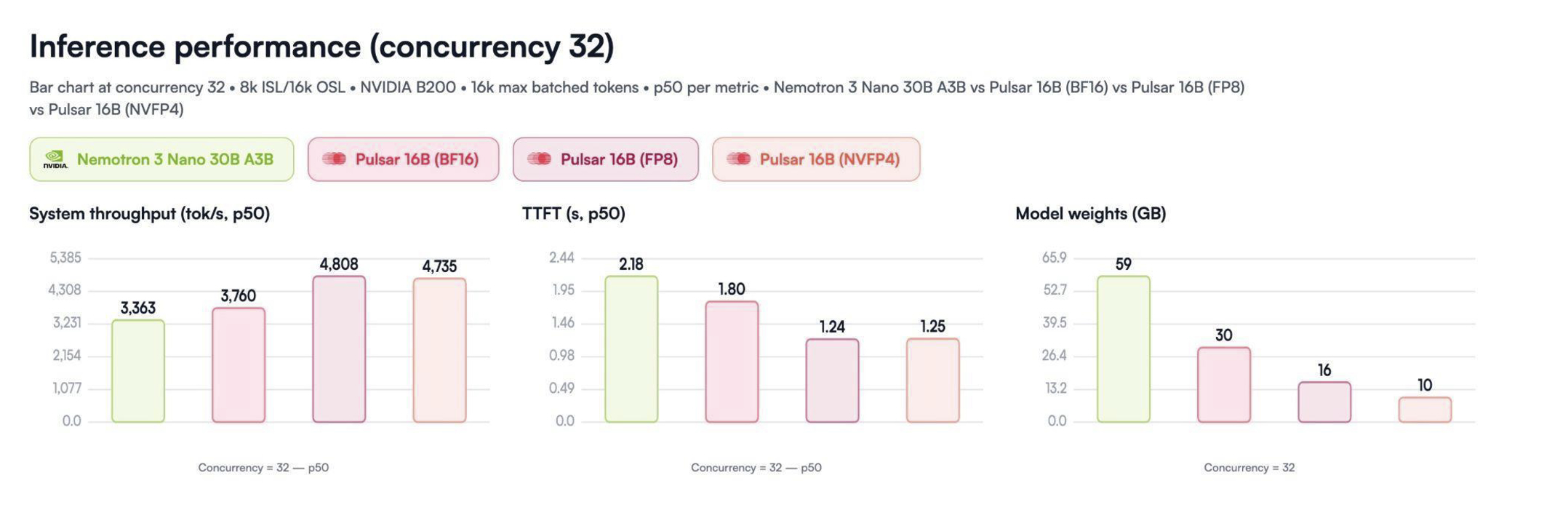
With 32 concurrent requests on an NVIDIA Blackwell GPU, Pulsar 16B (FP8) delivers 4,808 tokens/second system throughput, a 43% increase over the base model's 3,363 tok/s, while reducing time-to-first-token (TTFT) from 2.18s to 1.24s.
Long-context performance
Long-context performance is often where aggressive model compression silently degrades. Multiverse Computing evaluated Pulsar 16B across LongBench, AA-LCR, the RULER suite, and NIAH variants at progressively longer contexts. Needle-in-a-haystack retrieval remains essentially perfect on both sides of the 100K token mark, and Pulsar 16B tracks the uncompressed base model closely on harder RULER tasks at extended context. For document-intensive workloads, Pulsar 16B closely mirrors the behavior of the original model.
Architecture and compression methodology
Pulsar 16B is built on top of a compressed and optimized version of NVIDIA Nemotron 3 Nano, a Hybrid Mamba2-Transformer with Mixture-of-Experts. Multiverse Computing, a member of NVIDIA Inception, used NVIDIA's Model Optimizer and Megatron Bridge libraries as part of a compression workflow for its CompactifAI technology. The base model, nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16, has 31.6B total parameters with 3.5B active parameters. After compression, Pulsar 16B has 16.15B total parameters with 3.1B activated, with no retraining from scratch required.
Starting from that foundation, Multiverse Computing identified and removed mathematical redundancy within the trained network while preserving the reasoning behaviors learned during training. The result is a model that retains the same architecture family, prompt format, tool-calling structure, and reasoning interface as the Nemotron family at 16.15B parameters instead of 31.6B.
“Running advanced AI locally has historically required compromising on model size or performance,” said Enrique Lizaso, cofounder and CEO of Multiverse Computing. “What we’re demonstrating with Pulsar 16B is that frontier-grade reasoning can now be deployed without the overhead of cloud-scale infrastructure, at a footprint enterprises can actually run and scale economically.”
Pulsar 16B is designed for teams operating where the cost and footprint of frontier-class reasoning had previously been prohibitive, such as high-concurrency agentic workflows, continuously running long-document pipelines, and customer-facing assistant deployments. Single-node setups, regulated on-premises environments, and latency-sensitive systems all become viable deployment targets.
Pulsar 16B is available today on Hugging Face under the Apache 2.0 license. Full technical documentation, including methodology, evaluation setup, and per-benchmark results, is available at multiversecomputing.com. To explore Multiverse Computing’s open-source model releases, visit huggingface.co/MultiverseComputingCAI.
About Multiverse Computing
Multiverse Computing is a leader in sovereign AI for regulated industries. The company develops fast, efficient, and highly specialized AI models that enable organizations to deploy advanced artificial intelligence securely within their own infrastructure, ensuring full control over data, governance, and compliance. Serving sectors where privacy, reliability, and operational efficiency are critical, Multiverse helps enterprises unlock the value of AI while maintaining sovereignty over their most sensitive information. Headquartered in Donostia-San Sebastián, Spain, with offices in the United States, Canada, and across Europe, Multiverse serves more than 100 global customers, including Iberdrola, Bosch, and the Bank of Canada.
For more information, visit www.multiversecomputing.com
Media Contact
LaunchSquad for Multiverse Computing
multiverse@launchsquad.com
A photo accompanying this announcement is available at https://www.globenewswire.com/NewsRoom/AttachmentNg/71520b6b-cd84-4fce-8daf-a54716f8f665

![]()
Multiverse Computing Pulsar 16B Inference Performance

Inference performance
Legal Disclaimer:
EIN Presswire provides this news content "as is" without warranty of any kind. We do not accept any responsibility or liability for the accuracy, content, images, videos, licenses, completeness, legality, or reliability of the information contained in this article. If you have any complaints or copyright issues related to this article, kindly contact the author above.
